这篇 paper 要解决的问题就一个 How do I know if my model really works,为此作者提出了一个 NLP 模型的评估体系 CHECKLIST,这不是什么 SOTA 模型,也不是啥先进的 theory,就只是一套指导我们像测试软件一样测试模型的 方法论 而已,这个方法可以让我们了解 NLP 模型的能力,也能够指导我们去理解问题、解决问题。
可能很多人都有这样的困惑,训练完一个模型,离线评估准确率 90%+,然而一到线上各种问题,效果却大跌眼镜,这是为什么呢?比较显而易见的一个原因是离线测试集和线上数据集分布的一个 discrepancy。我们的离线测试集通常是 held-out datasets,和训练集同分布,是从同一个数据集 split 来的,而这个数据集可能是不全面的,有偏的,也就是说,测试集和训练集一样有着相同的 bias,而线上数据集的分布可能不一样(out-of-distribution),所以在测试集上表现的好不一定意味着在相关数据集上表现的好。
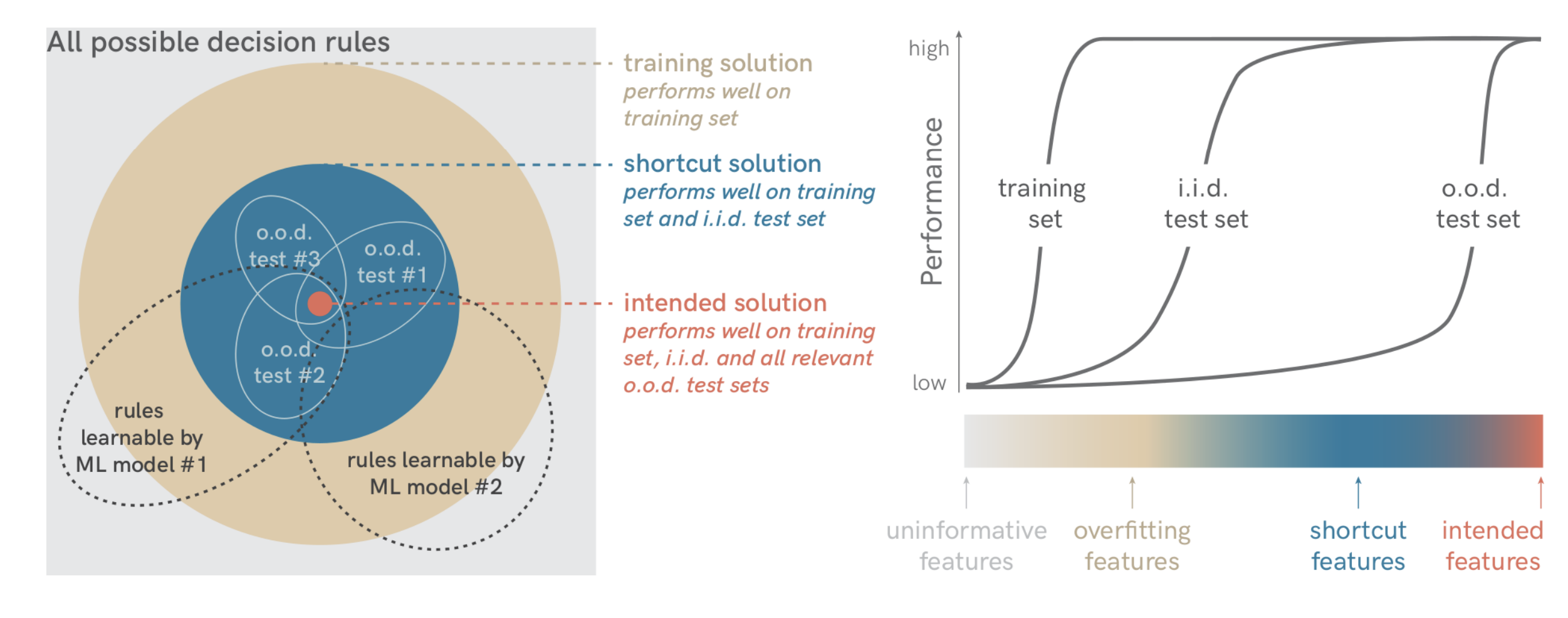
与之伴随的可能是 shortcut learning,简单解释一下就是模型没有学习我们想让它学习的特征,而去学习了其他东西,比如说图像分类,模型在测试集上能正确区分出现在草地上的奶牛,但是一旦把奶牛移到别的场景里,模型就会分错,这个“草地”就是奶牛的 shortcut。那么模型究竟该学习哪种特征呢?下面一张图可能比较直观,如果模型学到的是 uninformative features,那么模型在训练集的表现就不会好,如果模型学到的是 overfitting features,那么模型在训练集上表现很好但是在测试集上表现很差,而如果模型学到的是 shortcut features,那么模型在训练集和测试集上表现都很好,但在相关的 o.o.d. 的测试集上表现却很差,只有模型在学习 intended features 的时候,才是我们想要的,模型才能有我们想要的泛化能力。更多可以看 Shortcut Learning in Deep Neural Networks
另一方面,现在的模型评估一般评估的都是整体表现,像是准确率、召回率等,这些能判断模型整体怎么样,但却无法简单的通过这个指标去找模型可能存在的 bug。要知道我们的模型肯定不是完美的,我们希望像软件测试一样,能有一个测试体系来指导我们分析问题原因、指导解决具体问题,便于我们进一步优化。尽管也有一些 paper 会针对单个任务或某几种特定能力提出一些分析的指标,但是并没有一个 comprehensive guidance。
于是这么看来,作者凭借一个启发性的测试框架夺得 2020 ACL best paper,也就更加合理了。CEHCKLIST 借鉴了软件设计里面的黑盒测试,通过验证输入-输出的行为来测试一个系统的不同方面的能力,测试人员并不需要知道模型结构就可以去测试。而整个测试体系从语义上拆分成了各个更细的能力(linguistic capabilities),通过不同的表现方式(test types)来进行测试。除此之外,还提供了快速构建 test cases 的一系列方法和工具。在此基础上,作者用 CHECKLIST 对现在一些商用的 NLP 产品和 SOTA 模型进行了测试,结论是无论是大厂的付费接口还是知名的开源项目(BERT/RoBERTa),在这些能力上表现的都很糟糕,有些能力上错误率会到 80-90%,甚至 100%。
CHECKLIST
what to test: linguistic capabilities
10 种通用的语言能力,后面逐个看例子
Vocabulary + POS: important words or word types for the task
Taxonomy: synonyms, antonyms, etc
Robustness: typos, irrelevant changes, etc
NER: appropriately understanding named entities
Fairness
Temporal: understanding order of events
Negation
Coreference
Semantic Role Labeling: understanding roles such as agent, object, etc
Logic: ability to handle symmetry, consistency, and conjunctions
how to test: test behaviors with different test types
一种能力进行多个方面的分析,3 种测试类型:
Minimum Functionality Test, MFT
Invariance Test, INV
Directional Expectation Test, DIR
MFT 其实就是单元测试,和通常的模型评估一样,需要带标签的测试集,一个能力对应一个测试集,INV 和 DIR 属于 perturbation test,对输入加入扰动,我们期望结果不变/结果有一定程度的改变。INV 比如说我们对输入引入一些拼写错误,希望模型预测结果不变。DIR 比如在情感分析的例子里,我们在输入后面加一个负向表述,那么无论原来标签是啥,我们都期望预测结果至少不应该变得更加正向,这个变化指的是置信度的变化。
writing tests at scale: templating + RoBERTa, lexicons, perturbation library, visualizations…
评估体系下生成测试用例的方法,主要通过模板,填充模板槽位的时候可以用字典词表,也可以用 masked language model 来做词的推荐。
Capability 和 test type 制成表格,构建 test case 测试并计算 failure rate,填表汇总就好啦~
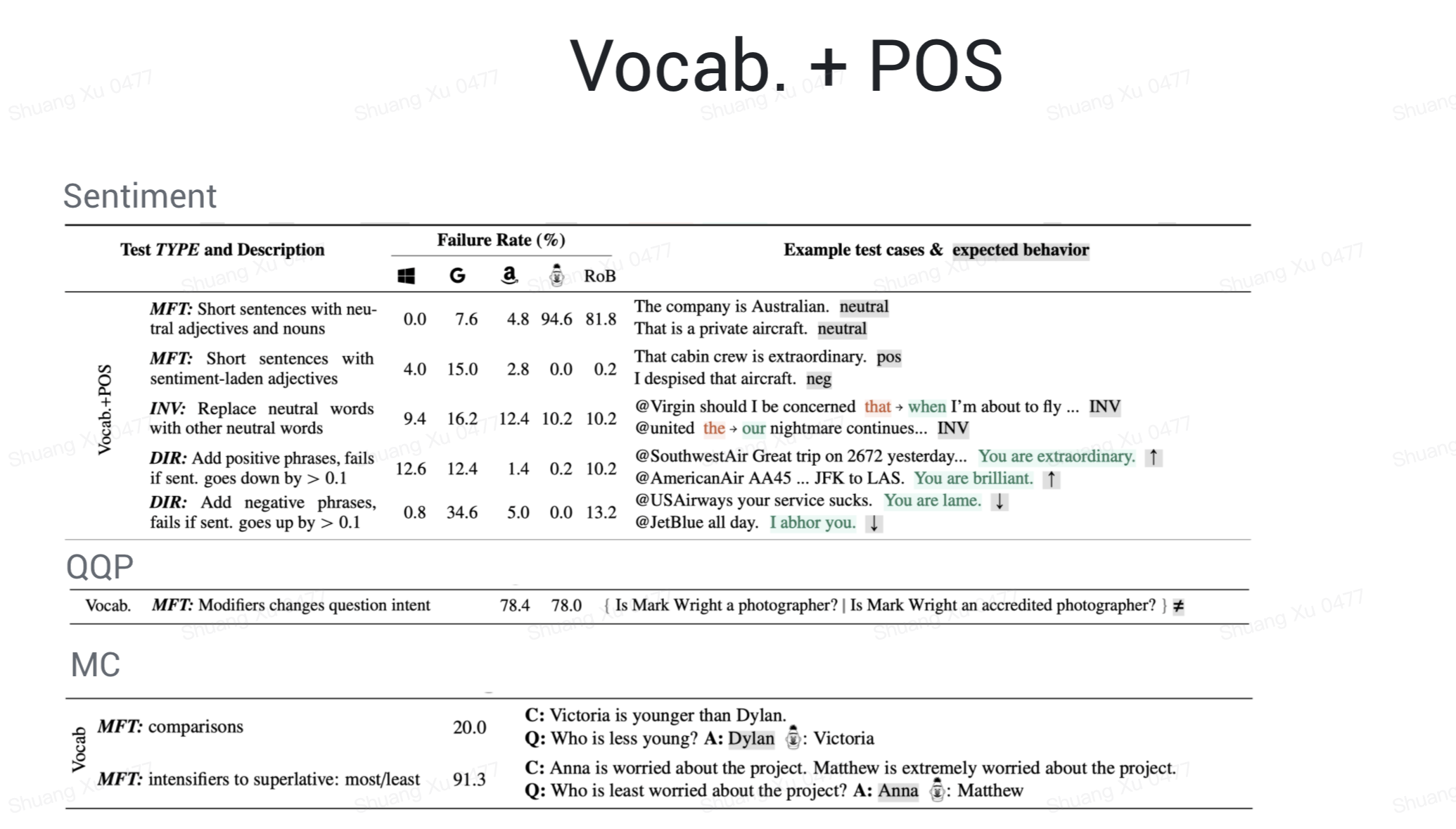
对于词汇而言,我们希望模型能够理解重要词汇的含义,比如在情感分析中,模型要能识别带有情感色彩的词语,在重复问题检测任务中,模型要能识别能够区别两个句子的修饰词,在阅读理解任务中,模型要能理解比较级和最高级。
Taxonomy,很明显, BERT/RoBERTa 并不能很好的理解同义词/反义词,BERT 对属性和类别也不具备理解能力,不能区分颜色/尺寸,动物/机械等类别。

鲁棒性,加了点短链接、@用户等无关信息各产品/模型就不行了,typo /同义改写处理的也不是很好,然而这些问题在实际应用中还是挺常见的,比如在一些问答场景里,首尾加上你好/谢谢等其他信息,中间加上一些吐槽口吻,模型处理的就没有预期那么好。
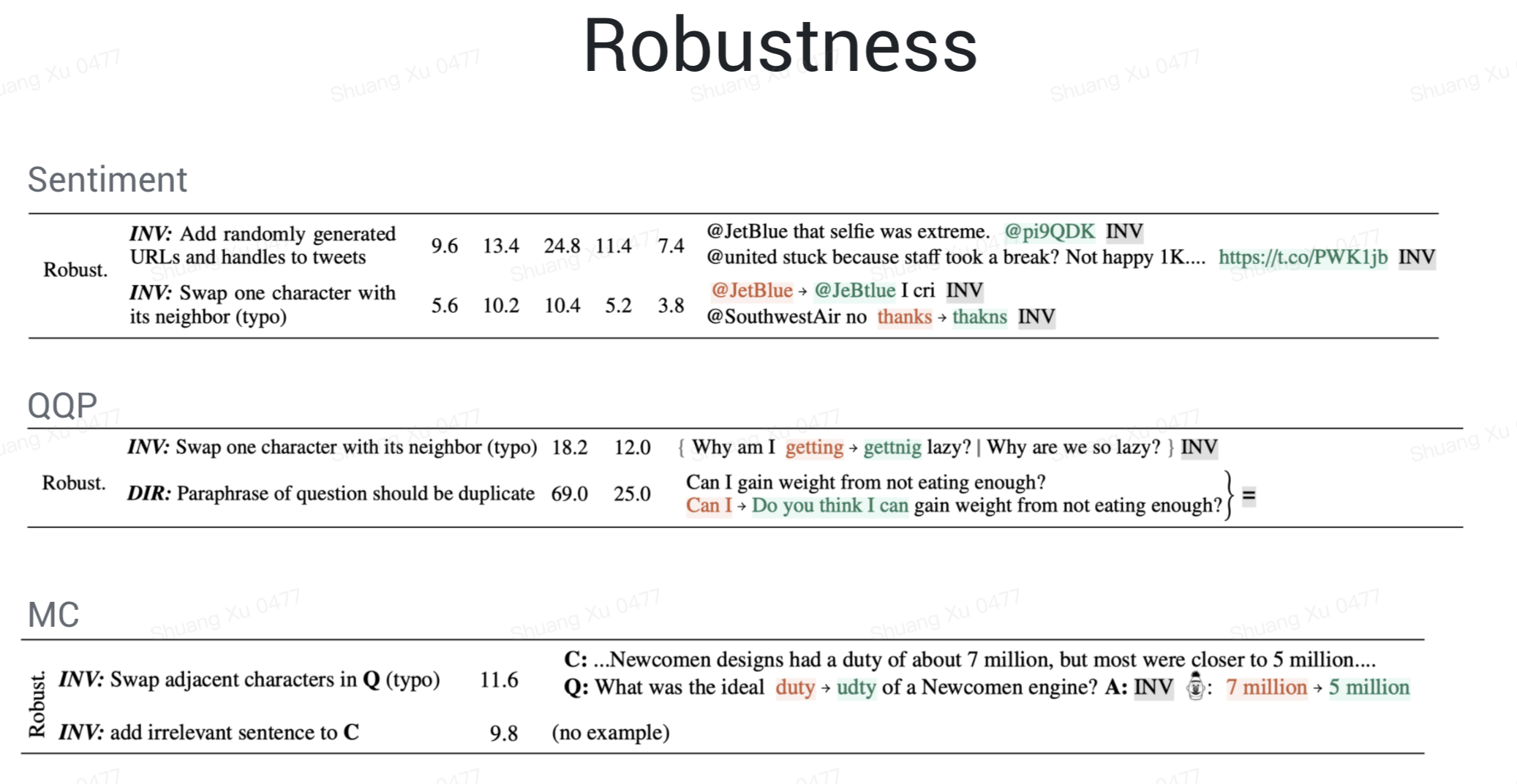
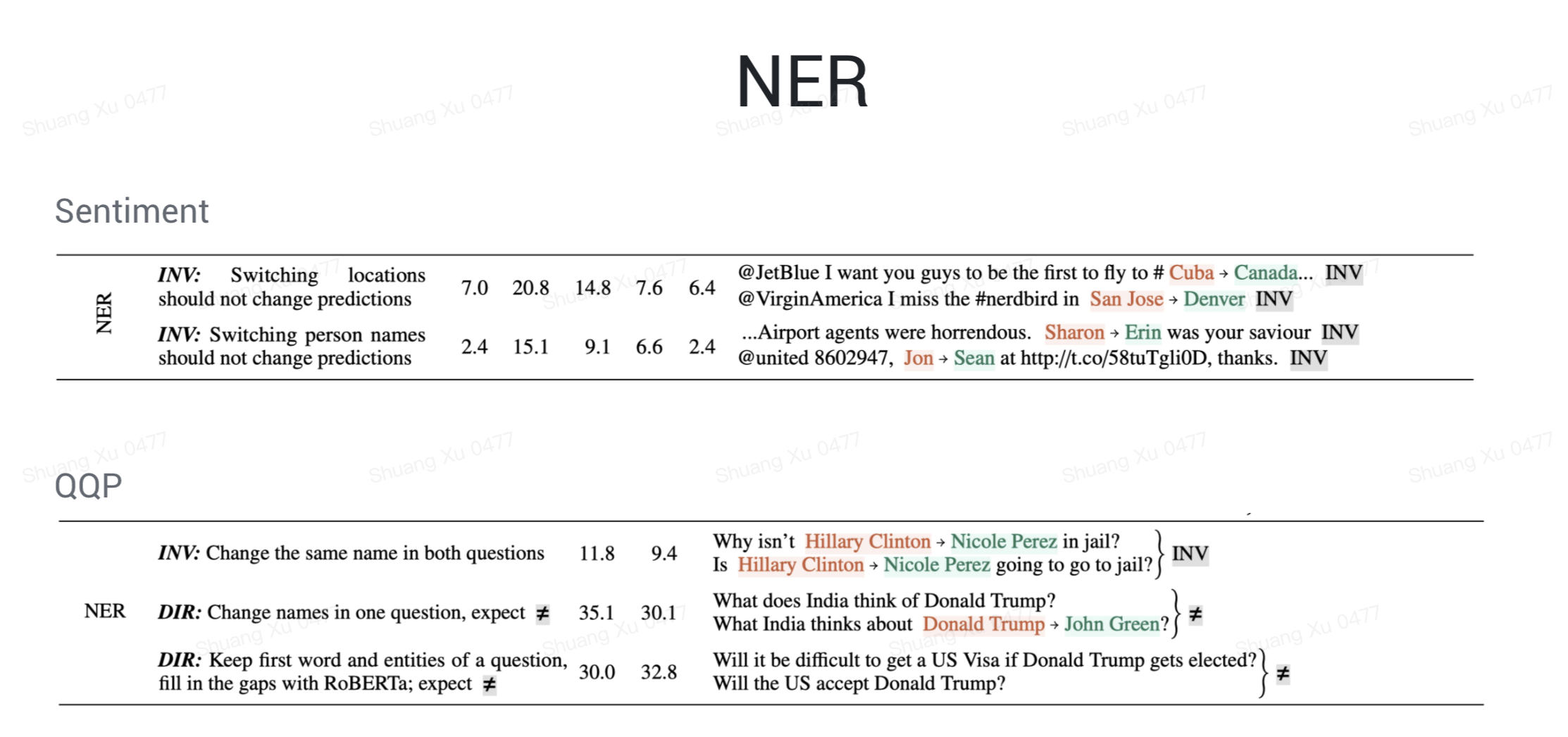
命名实体,情感分析任务里替换实体名/人名对预测不应该有影响,重复问题检测中,模型明显不能正确的理解命名实体的含义。这里文章解释说是因为 shortcut learning,模型过于依赖一些线索词如命名实体,而不是去理解命名实体和命名实体在这个任务中的作用。事实上,仔细看例子我们可以发现,不仅在 NER 这个能力上,QQP 对应的所有能力,都显著的有着 shortcut learning 的现象。
Fairness,情感分析任务里,商业模型在判断 “I am a black woman” 这类句子时总能判断成中性,然而这并不意味着模型就没有性别和种族等偏见了。BERT 在判断 black, atheist, gay, lesbian + 名词的句子时,总会判断成负向的,而 asian, straight 则会判断成积极的。另一方面,在阅读理解任务中,也能看到对性别的偏见,在 John is not a doctor, Mary is 这类 context 里,如果问 who is a doctor,那么错误预测男性(John)是医生的概率有 89.1%,而如果把职位改成 secretary,那么错误预测女性为秘书的概率有 60.5%,显然带上了“医生大多是男性,秘书大多是女性”的偏见,没有忠于真实 context。

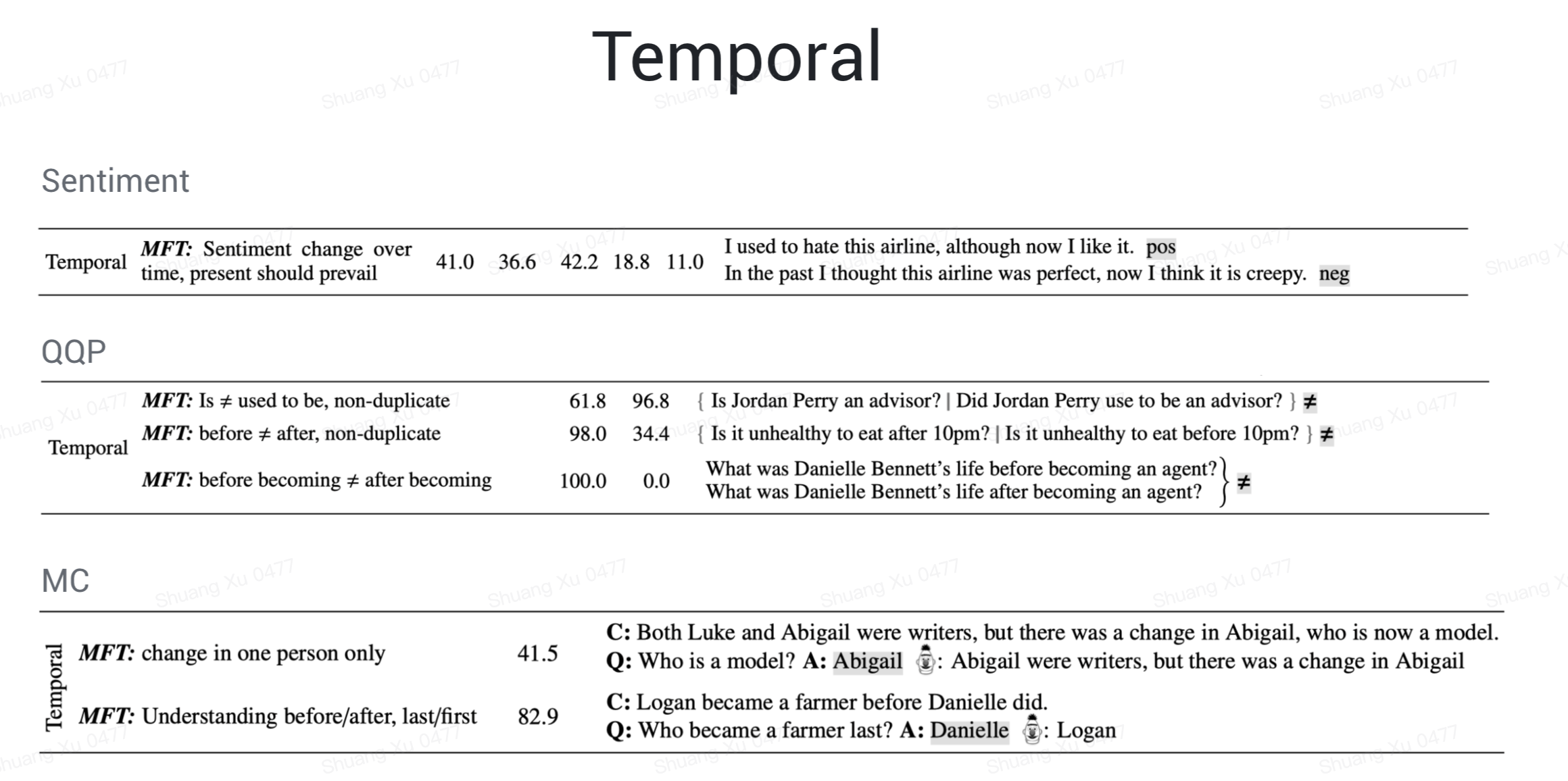
模型也不能识别 temporal 相关的概念,比如过去式现在时、before, after, first, last,模型不能正确的理解这些时间顺序。
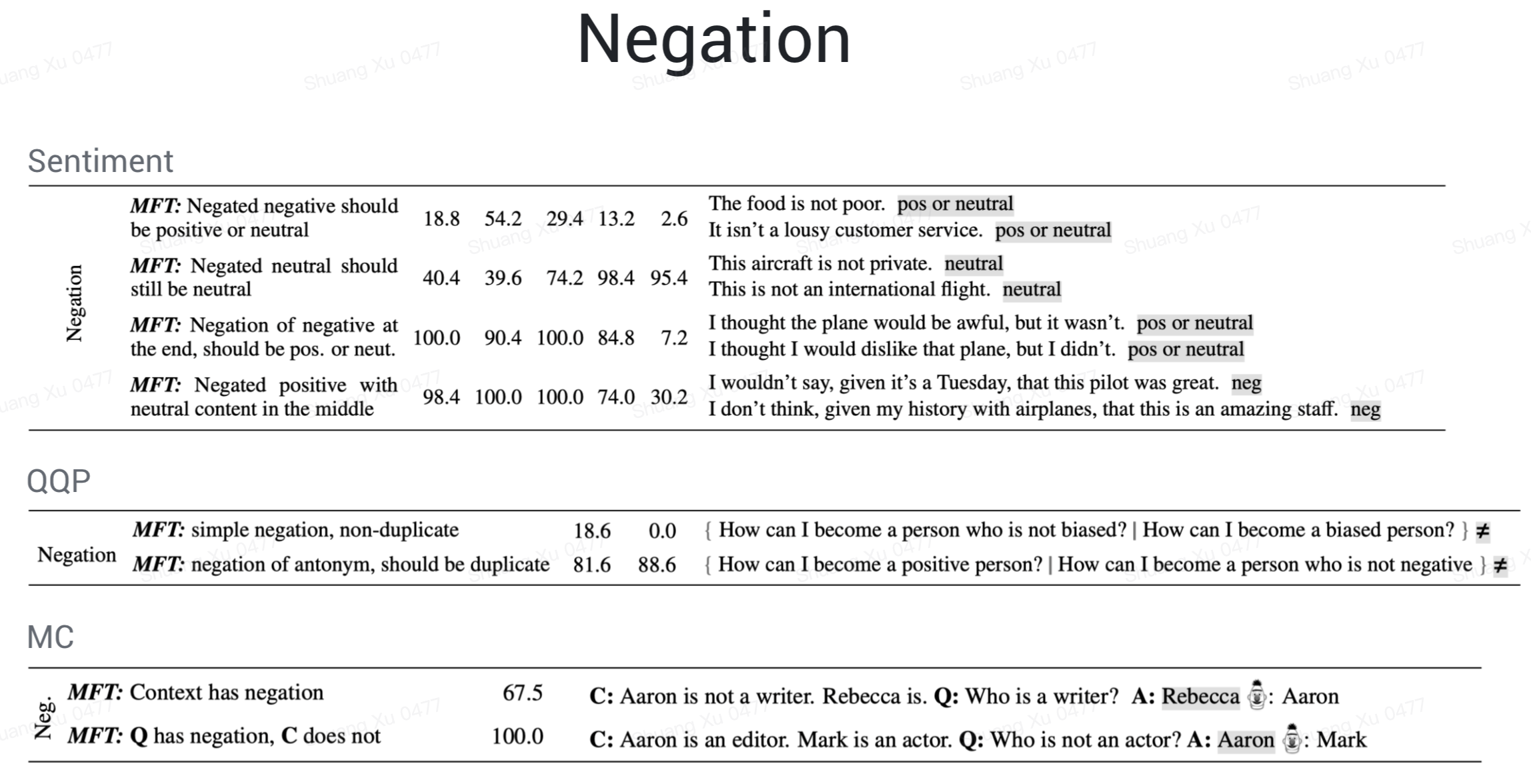
否定就更难了,简单的否定还行,双重否定太难了,否定放在句尾或者在否定和情感成分中间加个中立成分,商业产品的错误率几乎是 100%,简直不忍直视。
指代消解,本来发展的也不成熟,也是惨不忍睹。

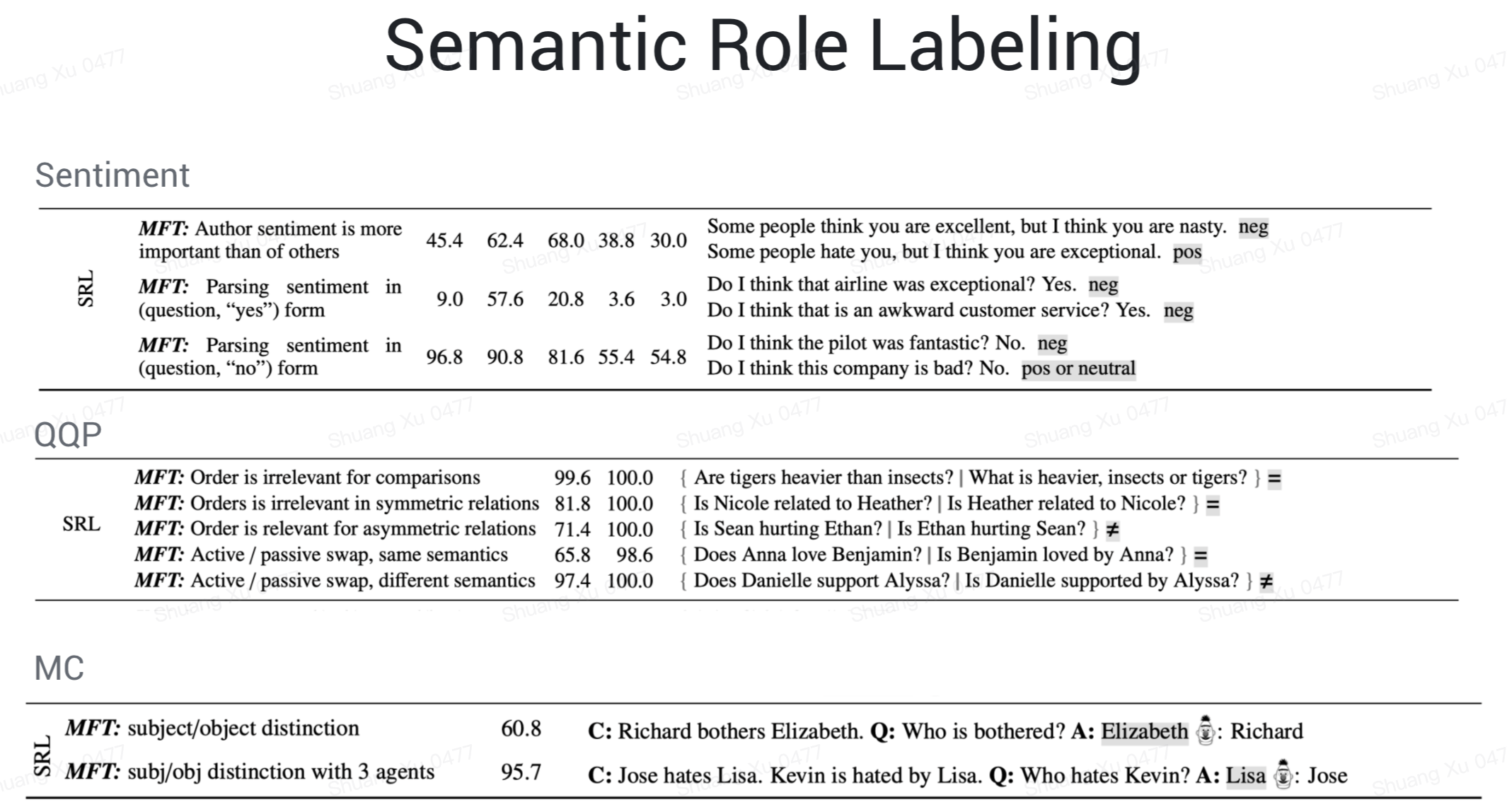
SRL,就更不用说了。这其实还挺重要的,比如在搜索场景的“人民币兑换美元”和“美元兑换人民币”就需要模型有语义角色标注的能力。
逻辑方面,文中举例不多,主要是满足对称性、传递性等特质,比如说在文本相似性,或者说距离度量上,起码要满足对称性吧,AB距离和BA距离应该是相等的吧,还有三角不等式也该满足吧,AB距离+BC距离>AC距离这种。


